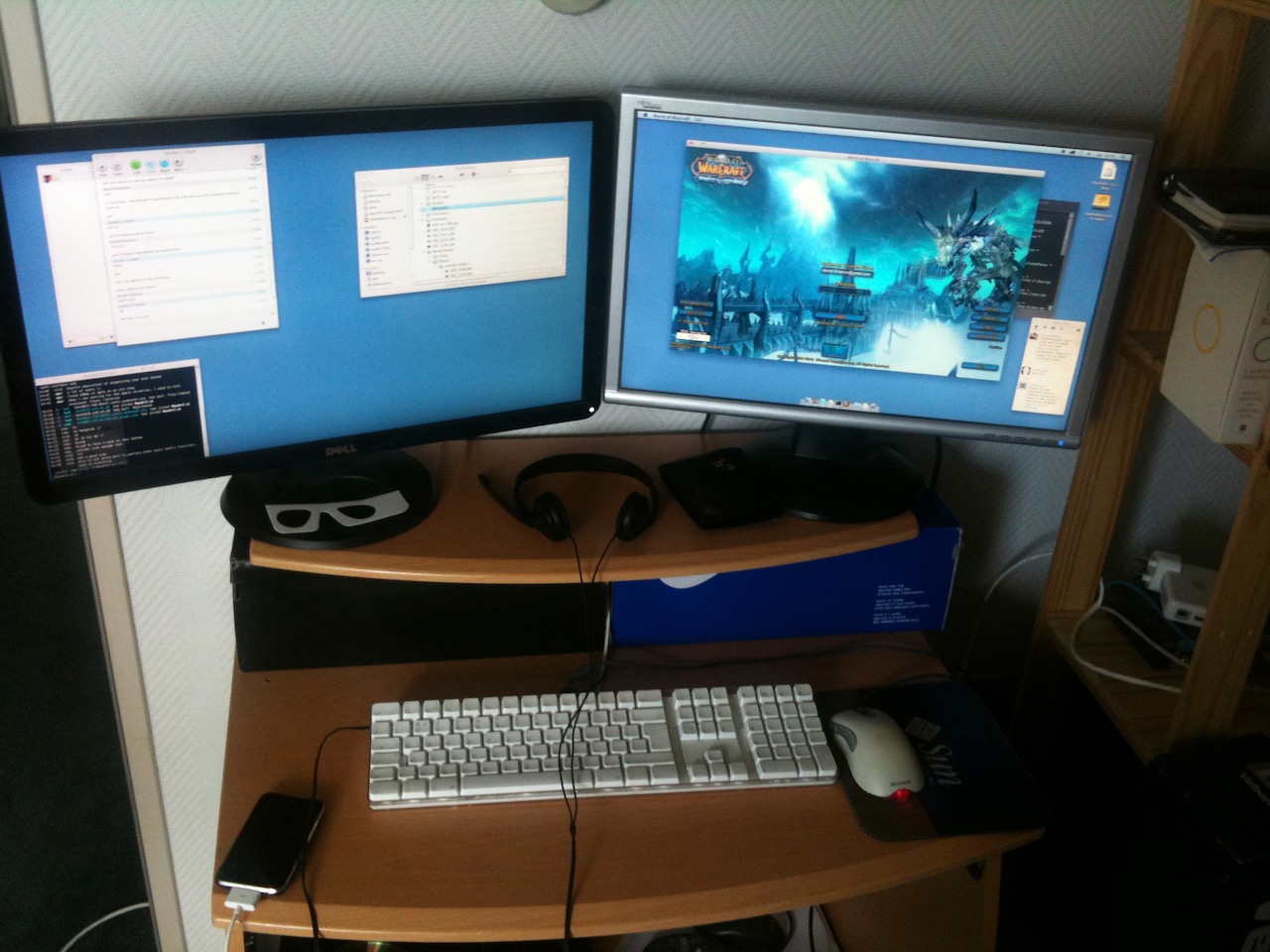
As much as I love a nice shiny laptop, i’ve been using a steadily evolving desktop machine for well over a decade. In fact I don’t think i’ve ever been without a workstation since I was first introduced to a computer:
In hindsight I realise that my current set up is actually pretty aged, but either I haven’t noticed or don’t care enough to upgrade. I also feel like i’ve been through a lot of Operating systems through my time:
At some point at University I started a part time job as a Macintosh repair/support person, which I used to hold the belief was my worst work experience. However, this exposed me to the world of Apple hardware and the symbiotic operating system. Well.. System7, MacOS 8 and MacOS 9 were pretty grim but some of the hardware 🤩. I remember one day someone bringing in a 20th Anniversary Mac The product was a complete failure, but look at it !
The G5 tower, such a clean yet imposing piece of metal.. pop the side off and it looked like the inside of a Dyson vacuum cleaner. I also got to work with the Apple rack mount hardware too, arguably the last time there would be anything aesthetically pleasing in a data centre.
Anyway… I was lucky enough to be given a Powerbook G4, it had been repaired and after 6 months the person had never collected it or replied to calls/emails ¯\_(ツ)_/¯ and thus began my switch over to OSX (then MacOS X and now MacOS, clearly naming is hard).
Hackintosh
With a shiny Powerbook in hand I proceeded to move all my daily content (music/photos) and social platform(s).. largely just last.fm, myspace and facebook at that point. My poor old workstation started to be turned on less and less as I started to find it slow and clunky when compared. In the mid 2000s Apple did the unthinkable (or maybe the thinkable, IBM were taking forever for a laptop G5 chip) and pivoted the Apple hardware away from PowerPC to Intel hardware, HOWEVER the OS whilst x86 is still tied to Apple specific hardware.
I honestly have no recollection where I found it (probably a dodgy torrent site), but I came across a OS X 10.4 DVD Image that was hacked to install on non Apple hardware and that was it!
Some looking around on archive.org has revealed that it was JaS OS Hackintosh OS images..
For the next couple of OS X releases all of the underlying work was largely taken care of and things “just worked”.. here I was with the Apple experience but without the additional cost!
Apple Airport on the shelf there, a fantastic Access point back in the day The Hackintosh’s endured a lot of my terrible skillz at WoW
Additional complexity
At some point the overhead of producing these packaged OS installers clearly wasn’t worth it (presumably Apple were making things additionally difficult) and suddenly a lot of the overhead was past down to the users. At this point Hackintosh users suddenly had to care about things like EFI/Bootloaders/Kexts and a raft of additional tooling 🤯.
To get a working system the following steps usually were required:
Get a USB stick
Create an EFI partition
Install a bootloader (clover was the one, back in the day) and kexts for your system
Get a MacOS X installer and write it to the USB stick
Boot from the USB stick and find that (Display/USB/Network/Disk etc.. didn’t work) go back to step 3
Install MacOS X to internal disk
Boot from USB Stick into Mac OSX on internal disk
Transfer working /EFI to internal disk and install any missing drivers/kernel modules
Hope Apple didn’t release anything new for a while…
Additionally in the middle of all this Nvidia had a falling out with Apple, meaning that Apple switched to AMD and immediately stopped any new drivers for Nvidia cards :-(
This was pretty much par for the course until MacOS Big Sur was released at which point a new boot loader was required (for reasons I’m not bothered to understand at this point)… Whilst this new bootloader allowed for installing these new MacOS releases, it incurs a significant overhead.. largely the managing of a LOT of XML. If by some chance you manage to incant a working /EFI configuration then lucky you, but it’s a slow and steady process involving many many many reboots and kernel panics. Luckily there is a pretty good community (it’s always about a strong community) in the hackintosh space both on reddit and in other places such as TonyMacx86. The community is pretty helpful at inspecting peoples XML and pointing out irregularities and mistakes and getting people on their way.
With a working /EFI I managed to move to OpenCore and finally stand up BigSur and then later on Monteray!
Today
So here we are.. to today (or the day I wrote this)..
Anyway, for “reasons” the /EFI partition is FAT (old Microsoft standard) which isn’t the most reliable during power loss… Inevitably I had a powercut a few days ago and my /EFI partition was wiped, which lost the entire contents of my finely tuned and artisanal XML config. At this point I couldn’t decide if I had the energy to go through this process again. But given the xmas break and prospect of having to speak with the in-laws I decided this might be an opportunity..
The process has improved since I followed the steps for BigSur, in fact the guide for OpenCore is fantastic and the additional drivers for USB/Audio just work™️ etc..
Get the OpenCore bootloader
Add in the ACPI tables for your architecture
Add in drivers that are needed
Fight with XML
Fight with XML more
Fight with XML even more
Profit?
Nope Yep
My trusty workstation is now back up and running on Ventura (although it doesn’t really seem like an OS for workstation use … )
The Future
The move to Intel allowed hackintosh’s to become a thing, however the recent move to ARM from Apple will probably be the final nail in the coffin in the community. It’s been a good run of running MacOS on my hardware, but it does leave me in a quandary of where to go next when I can no longer run a Hackintosh.
// So we have a Kubernetes cluster in r.Client, however we can't use it until the caches // start otherwise it will just return an error. So in order to get things ready we will // use our own client in order to get the key and set up the Google Maps client in advance config, err := restClient.InClusterConfig() if err != nil { kubeConfig := cmdClient.NewDefaultClientConfigLoadingRules().GetDefaultFilename() config, err = cmdClient.BuildConfigFromFlags("", kubeConfig) if err != nil { return err } } // create the clientset clientset, err := kubernetes.NewForConfig(config) if err != nil { panic(err.Error()) }
func (r *DirectionsReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) { // Set the log to an acutal value so we can create log messages log := log.FromContext(ctx) log.Info("Reconciling direction resources")
var directions katnavv1.Directions if err := r.Get(ctx, req.NamespacedName, &directions); err != nil { if errors.IsNotFound(err) { // object not found, could have been deleted after // reconcile request, hence don't requeue return ctrl.Result{}, nil } log.Error(err, "unable to fetch Directions object") // we'll ignore not-found errors, since they can't be fixed by an immediate // requeue (we'll need to wait for a new notification), and we can get them // on deleted requests. return ctrl.Result{}, client.IgnoreNotFound(err) } // your logic here log.Info("Determining journey", "Source", directions.Spec.Source, "Destination", directions.Spec.Destination)
$ kubectl get directions directions-to-sheffield -o yaml apiVersion: katnav.fnnrn.me/v1 kind: Directions metadata: annotations: kubectl.kubernetes.io/last-applied-configuration: | {"apiVersion":"katnav.fnnrn.me/v1","kind":"Directions","metadata":{"annotations":{},"name":"directions-to-sheffield","namespace":"default"},"spec":{"destination":"Sheffield, uk","source":"York, uk"}} creationTimestamp: "2021-07-28T14:34:56Z" generation: 2 name: directions-to-sheffield namespace: default resourceVersion: "6986253" uid: c4077b0b-8f2f-4fc3-82c0-2d690a24d98a spec: destination: Sheffield, uk source: York, uk status: directions: | Head southwest on Lendal Bridge/Station Rd/A1036 toward Rougier St/B1227Continue to follow A1036 Keep left to continue toward Station Rd/A1036 Continue onto Station Rd/A1036Continue to follow A1036 Turn right onto Blossom St/A1036Continue to follow A1036 At the roundabout, take the 2nd exit onto Tadcaster Rd Dringhouses/A1036 Take the ramp to Leeds Merge onto A64 Merge onto A1(M) via the ramp to Leeds/M1/Manchester/M62 Keep right at the fork to continue on M1 At junction 34, take the A6109 exit to Sheffield(E)/Rotherham(C)/Meadowhall At Meadowhall Roundabout, take the 4th exit onto Meadowhall Rd/A6109 Keep right to stay on Meadowhall Rd/A6109Continue to follow A6109 At the roundabout, take the 1st exit onto Brightside Ln/A6109Continue to follow A6109 Slight right onto Savile St/A6109 Turn right onto Derek Dooley Way/A61Continue to follow A61 Slight left onto Corporation St/A61 Slight left onto Corporation St/B6539 At the roundabout, take the 2nd exit onto W Bar Green/B6539Continue to follow B6539 At the roundabout, take the 3rd exit onto Broad Ln/B6539Continue to follow B6539 At the roundabout, take the 1st exit onto Upper Hanover St Continue onto Hanover Way At the roundabout, take the 1st exit onto Moore St Continue onto Charter Row Continue onto Furnival Gate Furnival Gate turns left and becomes Pinstone St Turn right onto Burgess St Burgess St turns right and becomes Barker's Pool Barker's Pool turns left and becomes Leopold St distance: 93.8 km duration: 'Total Minutes: 77.816667' endLocation: Sheffield, UK routeSummary: M1 startLocation: York, UK
This is a rough shopping list of skills/accounts that will be a benefit for this guide.
Equinix Metal portal account
GO experience (basic)
iptables usage (basic)
qemu usage (basic)
Our Tinkerbell server considerations
Some “finger in the air” mathematics are generally required when selecting an appropriately sized physical host on Equinix metal. But if we take a quick look at the expected requirements:
We can see that the components for the Tinkerbell stack are particularly light, with this in mind we can be very confident that we can have all of our userland components (tinkerbell/docker/bash etc..) within 1GB of ram and leave all remaining memory for the virtual machines.
That brings us onto the next part, which is how big should the virtual machines be?
In memory OS (OSIE)
Every machine that is booted by Tinkerbell will be passed the in-memory Operating System called OSIE which is an alpine based Linux OS that ultimately will run the workflows. As this is in-memory we will need to account for a few things (before we even install our Operating System through a workflow.
OSIE kernel
OSIE RAM Disk (Includes Alpine userland and the docker engine)
Action images (at rest)
Action containers (running)
The OSIE Ram Disk whilst it looks like a normal filesystem is actually held in the memory of the host itself so immediately will withhold that memory from other usage.
The Action image will be pulled locally from a repository and again written to disk, however the disk that these images are written to is a ram disk, so these images will again withhold available memory.
Finally, these images when ran (Action containers) will have binaries in them that will require available memory in order to run.
The majority of this memory usage from the as seen from above is for the in-memory filesystem in order to host the userland tools and the images listed in the workflow. From testing we’ve normally seen that >2GB is required, however if your workflow consists of large action images then this will need adjusting accordingly.
With all this in consideration, it is quite possible to run Tinkerbell on Equinix Metals smallest offering the t1.small.x86, however if you’re looking at deploying multiple machines with tinkerbell then ideally a machine with 32GB of ram will comfortably allow a comfortable amount of headroom.
Recomended instances/OS
Check the inventory of your desired facility, but the recommended instances are below:
c1.small.x86
c3.small.x86
x1.small.x86
For speed of deployment and modernity of the Operating System, either ubuntu 18.04 or ubuntu 20.04 are recommended.
Deploying Tinkerbell on Equinix Metal
In this example I’ll be deploying a c3.small.x86 in the Amsterdamn faclity ams6 with ubuntu 20.04. Once our machine is up and running, we’ll need to install our required packages for running tinkerbell and our virtual machines.
Change the bridgeName: from plunder to tinkerbell, then run shack network create. This will create a new interface on our tinkerbell bridge
Run shack network create
Test virtual machine creation
1 2 3 4 5 6 7
shack vm start --id f0cb3c -v <...> shack VM configuration Network Device: plndrVM-f0cb3c VM MAC Address: c0:ff:ee:f0:cb:3c VM UUID: f0cb3c VNC Port: 6671
We can also examine that this has worked, by examining ip addr:
1 2 3 4 5 6 7 8 9 10
11: plunder: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default link/ether 2a:27:61:44:d2:07 brd ff:ff:ff:ff:ff:ff inet 192.168.1.1/24 brd 192.168.1.255 scope global plunder valid_lft forever preferred_lft forever inet6 fe80::bcc7:caff:fe63:8016/64 scope link valid_lft forever preferred_lft forever 12: plndrVM-f0cb3c: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel master plunder state UP group default qlen 1000 link/ether 2a:27:61:44:d2:07 brd ff:ff:ff:ff:ff:ff inet6 fe80::2827:61ff:fe44:d207/64 scope link valid_lft forever preferred_lft forever
Connect to the VNC port with a client (the random port generated in this example is 6671).. it will be exposed on the public address of our equinix metal host.
git clone https://github.com/tinkerbell/sandbox.git cd sandbox
Configure the sandbox
1 2
./generate-envrc.sh plunder > .env ./setup.sh
Start Tinkerbell
1 2 3 4
# Add Nginx address to Tinkerbell sudo ip addr add 192.168.1.2/24 dev plunder cd deploy source ../.env; docker-compose up -d
At this point we now have a server with available resource, we can create virtual machines and tinkerbell is listening on the correct internal network!
Create a workflow (debian example)
Clone the debian repository
1 2 3
cd $HOME git clone https://github.com/fransvanberckel/debian-workflow cd debian-workflow/debian
Build the debian content
1 2 3
./verify_json_tweaks.sh # The JSON syntax is valid ./build_and_push_images.sh
Edit configuration
Modify the create_tink_workflow.sh so that the mac address is c0:ff:ee:f0:cb:3c, this is the mac address we will be using as part of our demonstration.
For using VNC, modify the facility.facility_code from "onprem" to "onprem console=ttys0 vha=normal". This will ensure all output is printed to the VNC window that we connect to.
Create the workflow
Here we will be asked for some password credentials for our new machine:
1
./create_tink_workflow.sh
Start our virtual host to install on!
1 2 3 4 5 6 7
shack vm start --id f0cb3c -v <...> shack VM configuration Network Device: plndrVM-f0cb3c VM MAC Address: c0:ff:ee:f0:cb:3c VM UUID: f0cb3c VNC Port: 6671
We can now watch the install on the VNC port 6671
Troubleshooting
1
http://192.168.1.1/undionly.pxe could not be found
If a machine boots and has this error it means that it’s workflow has been completed, in order to boot this server
1
could not configure /dev/net/tun (plndrVM-f0cb3c): Device or resource busy
This means that an old qemu session left an old adapter, we can remove it with the command below:
ip link delete plndrVM-f0cb3c
1
Is another process using the image [f0cb3c.qcow2]?
We’ve left an old disk image laying around, we can remove this with rm
In this post i’ve a bunch of things I want to cover all about Type:LoadBalancer (or in most cases a VIP (Virtual IP address). In most Kubernetes environments a user will fire in some yaml defining a LoadBalancer service or do a kubectl expose and “magic” will occur. As far as the end-user is concerned their new service will have a brand new IP address attached to it and when an end-user hits that IP address their traffic will hit a pod that is attached to that service. But what’s actually occuring in most cases? Who can provide this address? How does it all hang together?
A lot of this is already mentioned above, but put simply a service is a method of providing access to a pod or number of pods either externally or internally. A common example is exposing a web server front end, where we may have a deployment of 10 nginx pods.. we need to allow end users to access these 10 pods. Within Kubernetes we can define a service that is attached to this deployment, and thanks to the logic within Kubernetes we don’t need to concern ourselves too much with these pods.. we can scale up/scale down.. kill pods etc.. as long as we’re coming through the service it will always have an upto date list of the pods underneath it.
Types of service
ClusterIP
This is an internal only service.. typically used for internal communication between two services such as some middlewhere level connectivity.
NodePort
A NodePort is a port created on every node in the cluster. An external user can connect to a node address on this port to access the service. If we were to use a NodePort with nginx then we’d be given a high port (usually 30000+) that will route traffic to the nginx ports e.g. worker0xx:36123 --> [nginx-pod0x:80]
LoadBalancer
The LoadBalancer service is used to allow external access into a service, it usually requires something external (Cloud Controller Manager) to inform the Kubernetes API what external address traffic should be accepted on.
ExternalName
This allows a service to be exposed on an external name to point to something else. The main use-case is being able to define a service name and having it point to an existing external service…
The Kubernetes Load Balancer service
So how does all this hang together…
-> also i’ll be walking through how you can implement this yourself NOT discussing how the big cloud providers do it :-)
If you take a “fresh” Kubernetes cluster and create a simple nginx deployment and try to expose it as a LoadBalancer you’ll find that it doesn’t work (or sits in pending).
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE my-service LoadBalancer 10.3.245.137 <pending> 8080/TCP 54s
Why??? Well the Type:LoadBalancer isn’t the responsibility of kubernetes, it effectively doesn’t come out of the box… as we can see the internal IP (CLUSTER-IP) has been created but no external address exists. This EXTERNAL-IP is typically a piece of information that is infrastructure specific, in the cloud we need addresses to come from their IP address management systems and on-premises who knows how addresses are managed ¯\_(ツ)_/¯
Cloud Controller Manager
The name can be slightly confusing as anyone can write a CCM and their roles aren’t necessarily cloud specific, i presume it’s more that their main use-case is to extend a kubernetes cluster to be aware of a cloud providers functionality.
I’ve covered Cloud Controllers before, but to save the dear reader a few mouse-clicks i’ll cover it briefly again… The role of a CCM is usually to plug into the Kubernetes API and watch and act upon certain resources/objects. For objects of type node then the CCM can speak with the infrastructure to verify that the nodes are deployed correctly and enable them to handle workloads. The objects of type LoadBalancer would require the CCM to speak with an API to request an IP address that is available to be an EXTERNAL-IP, alternatively a CCM may be configured with an IP address range it can use in order to configure the EXTERNAL-IP.
LoadBalancer watcher
Within the CCM it will have code that will be watching the Kubernetes API, specifically for watching Kubernetes services… When one has the spec.type = LoadBalancer then the CCM will act!
Before the CCM has chance to act, this is what the service will look like:
We can see that the status is blank and the spec.loadBalancerIP doesn’t exist.. well, whilst we’ve been reading this the CCM has acted.. if we’re in the cloud it’s done some API calls or if we’re running our own it may have looked at it’s pool of addresses and found a free address. The CCM will take this address and modify the object by updating the spec of the service.
That is all the CCM needs to do although but your service will still be <pending> as the status is still blank :-(
Two other things need to happen at this point!
Kubernetes Services proxy
What is this “proxy” I speak of! … well, if you’ve noticed the kube-proxy pod on your cluster and wondered why it’s there then read on!
There is plenty more detail => here, but i’ll break it down mainly for LoadBalancers.
When we expose a service within Kubernetes, then the API server will instruct the kube-proxy to inject a bunch of rules into iptables/ipvs that will effectively capture traffic and ensure that this traffic goes to the pods defined under the service. By default any service we create will have its clusterIP and a port written into these rules so that regardless which node inside the cluster we try to access this clusterIP:port then the services proxy will handle this traffic and distribute it accordingly. The clusterIP are virtual IP addresses that are managed by the Kubernetes API, however with LoadBalancers the traffic is external and we don’t know what the IP address will be ¯\_(ツ)_/¯!
Well, as shown above the CCM will eventually modify the spec.loadBalancerIP with an address from the environment.. once this spec is updated then the API will instruct kube-proxy to ensure that any traffic for this externalIP:port is also captured and proxied to the pods underneath the service.
We can see that these rules now exist by looking at the output for iptables-save, all traffic for the address of the LoadBalancer is now forwarded on…
The final piece of the puzzle is getting traffic to the machines themselves …
External traffic !
So between a CCM and the Kubernetes service proxy, we have been given an external IP address that we have for our service and the Kubernetes service proxy will ensure that any traffic in the cluster for that external IP address is distributed to the various pods. We now need to get traffic to the nodes themselves…
Hypothetically, if we had a second network adapter in one of the nodes then we could configure this network adapter with the externalIP and as long as we can route traffic to that IP address then the kubernetes service proxy will capture and distribute that traffic. Unfortunately that is a very manual operation, so what options/technologies could we adopt in order to manage this?
We would usually need a final running piece of software that “watches” a service, and once the service is updated with a spec.loadBalancerIP from the CCM we know that it’s good to advertise to the outside world! Also once we’re exposing this to the outside world we can modify the status of the service with the address that we’re exposing on so that clients and end-users know that they can now use this address!
There are two main technologies that we can use to tell an existing environment about our new loadBalancer address, and when someone accesses this address where to then send the traffic!
ARP
ARP (Address resolution Protocol) is a Layer 2 protocol, who has the main task of working out which hardware (MAC address) an IP address belongs to. When an IP address first appears on the network it will typically broadcast to the network that it exists, it will also broadcast the MAC address of the adapter that it’s bound to. This informs the network of this IP <==> MAC binding, meaning that on a simple network when packets need to go to an IP address the switching infrastructure knows which machine to send the traffic.
We can see this mapping by using the arp command:
1 2 3 4 5 6 7 8
$ arp -a _gateway (192.168.0.1) at b4:fb:e4:cc:d3:80 [ether] on ens160 ? (10.0.73.65) at e6:ca:eb:b8:a0:f3 [ether] on cali43893380087 ? (192.168.0.170) at f4:fe:fb:54:89:16 [ether] on ens160 ? (10.0.73.67) at 52:5c:1b:5f:e1:50 [ether] on cali0e915999b8d ? (192.168.0.44) at 00:50:56:a5:13:11 [ether] on ens160 ? (192.168.0.45) at 00:50:56:a5:c1:86 [ether] on ens160 ? (192.168.0.40) at 00:50:56:a5:5f:1d [ether] on ens160
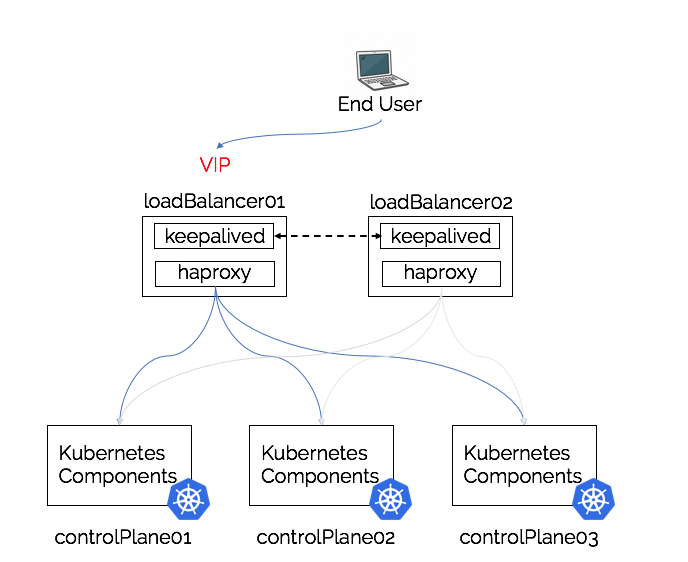
Load Balancing NOTE: In order for this to work with out Kubernetes cluster, we would need to select a single node that would become in charge of hosting this externalIP and using ARP to inform the network that traffic for this address should be sent to that machine. This is because of two reasons:
If another machine broadcasts an ARP update then existing connections will be disrupted
Multiple machines can’t have the same IP address exposed on the same network
The flow of operation is:
A leader is selected
spec.loadBalancerIP is updated to 147.75.100.235
147.75.100.235 is added as an additional address to interface ens160
ARP broadcasts that traffic to 147.75.100.235 is available at 00:50:56:a5:4f:05
Update the service status that the service is being advertised
At this point the externalIP address is known to the larger network, and any traffic will be sent to the node that is elected leader. Once the traffic is captured by the rules in the kernel, the traffic is then sent to the pods that are part of the service.
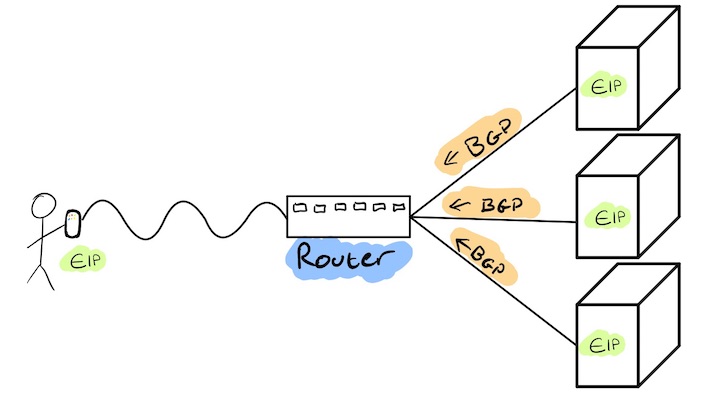
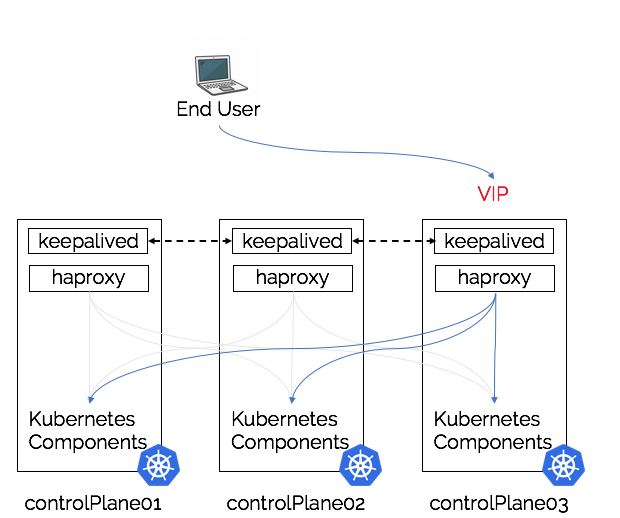
BGP
BGP (Border Gateway Protocol) is a Layer 3 protocol, the main task is to update routers with the path to new routes (that new route can be a single address or a range of addresses). For our use-cases in a Kubernetes cluster we would use BGP to announce to the routers in the infrastructure that traffic for a our spec.loadBalancerIP should be sent to one or more machines.
Load Balancing NOTE: One additional benefit over ARP is that multiple nodes can advertise the same address, this actually provides both HA and load-balancing across all nodes advertising in the cluster. In order to do this, we can bind the externalIP to the localhost adapter (so it’s not present on the actual network) and leave it to the kernel to allow traffic from the routers into the kernel and allow it to be proxied by kube-proxy.
The flow of operation is:
spec.loadBalancerIP is updated to 147.75.100.235
147.75.100.235 is added as an additional address to interface lo
A BGP peer advertisement updates the other peers (routers) that the loadBalancerIP is available by routing to the machines address on the network (all machines can/will do this)
Update the service status that the service is being advertised
Any client/end-user that tries to access 147.75.100.235 will have their traffic go through the router, where a route will exist to send that traffic to one of the nodes in the cluster, where it will be passed to the kubernetes service proxy.
Overview
At this point we can see there are a number of key pieces amd technologies that can all be harnesed to put together a load-balancing solution for Kubernetes. However the CCM is arguably the most important, as the CCM has the role of being “aware” of the topology or architecture of the infrastructure. It may need to prep nodes with configuration details (BGP configuration settings etc.) and speak with other systems to request valid addresses that can be used for the loadBalancer addresses.
Since starting at Packet Equinix Metal i’ve had to spend a bit of time getting my head around a technology called BGP. This is widely used at Equinix Metal, the main use case is to allow an Elastic IP address to route traffic externally (i.e. from the internet) into one or more physical machines in Equinix’s facilities. An external address will usually be routed into one of the Equinix datacenters, we can configure physical infrastructure to use this external IP and communicate to the networking equipment in this facility (using BGP) that traffic should be routed to these physical servers.
I’ve since been working to add BGP functionality to a Kubernetes load-balancing solution that i’ve been working on in my spare time kube-vip.io. This typically works in exactly the same method as described as above, where an EIP is advertised to the outside world and the BGP functionality will route external traffic to worker nodes and, where the service traffic is then handled by the service “mesh” (usually iptables rules capturing service traffic) within the cluster.
I’m hoping to take this functionality further and decided it would be nice to try and emulate the Equinix Metal environment as much as possible, i.e. having BGP at home. There are two methods that I could go down in order to have this sort of functionality within my house:
Create a local linux router, with it’s own network and use bgpd so I can advertise routes
Utilise my Unifi router, which after some light googling it turns out supports bgp
Given that: a. It’s Sunday b. I’m Lazy c. The instructions for setting up a local linux router looked like a pita I opted to just use my USG. d. The USG will enable me to advertise addresses on my existing network and the USG will route traffic the advertising hosts without me doing anything (exacerbating the laziness here)
Configuring the Unifi Security Gateway
These instructions are for the Unifi Security Gateway, however I suspect that the security gateway that is part of the “dream machine” should support the same level of functionality.
Before we begin we’ll need to ensure that we understand the network topology of the network so that we can configure for bgp to function as expected.
Device
Address
gateway
192.168.0.1
…
k8sworker01
192.168.0.70
k8sworker02
192.168.0.71
k8sworker03
192.168.0.72
In the above table we can see a subset of hosts on my network, the first host that is important is the gateway address on my network (which is the address of the USG). All hosts on my network have this set as the default gateway, which means that when a machine needs to access an IP address that isn’t192.168.0.1-254 then it will send the traffic to the gateway for it to be routed to that specific address.
Your gateway can be found by doing something like the following:
1 2
$ ip route | grep default default via 192.168.0.1 dev ens160 proto static
The other addresses that are worth noting are the three worker hosts in my Kubernetes cluster that will advertise their bgp routes to the gateway.
NOTE: All of the next steps require ssh access into the appliance in order to enable and configure the USG so that bgp is enabled on the network.
If you don’t know your ssh password for your gateway then help is at hand.. because for some bizarre reason you can get the ssh username/password straight from the web UI.. Navigate to Network Settings -> Device Authentication and here you’ll find the ssh username and password.
NOTE 2: Whilst it is possible to enable bgp functionality through the cli, the actual web client isn’t aware of the bgp configuration. This will result in the bgp configuration being wiped when you do things like modify firewall rules or port forwarding in the web UI.
Enabling BGP
To begin with we’ll need to ssh to the Unifi USG with the credentials that can be found from the web portal.
Below is the configuration that we’ll add, i’ll break it down below:
1 2 3 4 5 6 7 8
configure set protocols bgp 64501 parameters router-id 192.168.0.1 set protocols bgp 64501 neighbor 192.168.0.70 remote-as 64500 set protocols bgp 64501 neighbor 192.168.0.71 remote-as 64500 set protocols bgp 64501 neighbor 192.168.0.72 remote-as 64500 commit save exit
configure - will enable the configuration mode for the USG.
set protocols bgp 64501 parameters router-id 192.168.0.1 - will enable bgp on the USG with the router-id as it’s IP address 192.168.0.1 the AS number 64501 is used to determine our particular bgp network
set protocols bgp 64501 neighbor x.x.x.x remote-as 64500 - will allow our bgp instance to take advertised routes from x.x.x.x with the AS identifier 64500
commit | save - will both enable and then save the configuration
This is it.. the USG is now configured to take routes from our Kubernetes workers!!!
Configuring Kube-Vip
I’ve recently started on a release of kube-vip that will provide additional functionality in order to automate some of the bgp configuration, namely the capability to determine the host IP address for the bgpserver-id for advertising from a pod.
We can follow the guide for setting up kube-vip with bgp with some additional modifications show below!
Ensure that the version of the kube-vip image is 0.2.2 or higher
The bgp_routerinterface will autodetect the host IP address of the interface specified and this will become our server-id for each pods bgp peering configuration. The bgp_peer<as|address> is the remote configuration for our USG as specified above.
Testing it out !
Create a easy deployment, we can use the nginx demo for this:
Given that the USG is our default gateway we can actually advertise any address we like as a type:LoadBalancer and when we try and access if from inside the network the USG will route us back to the the Kubernetes servers!
For example we can create a load-balancer with the address 10.0.0.1
Given the home network is in the 192.168.0.0/24 range anything that is outside of it will need to go through our USG router, where we’ve advertised (through BGP) that traffic needs to come to any of the Kubernetes workers.
We can see this below on the USG with show ip bgp
1 2 3 4 5 6 7 8 9 10
admin@Gateway:~$ show ip bgp BGP table version is 0, local router ID is 192.168.0.1 Status codes: s suppressed, d damped, h history, * valid, > best, i - internal, r RIB-failure, S Stale, R Removed Origin codes: i - IGP, e - EGP, ? - incomplete
Network Next Hop Metric LocPrf Weight Path * i10.0.0.1/32 192.168.0.45 100 0 i *>i 192.168.0.44 100 0 i * i 192.168.0.46 100 0 i
In this post I’m going to cover the options that are typically available to an end user when looking to install an Operating System (mainly Linux, but I may touch on others 🤷) , we will touch on their pros/cons and look at what the alternatives are. We will then discuss concepts of immutable Operating System deployments and how we may go about doing so, including the existing eco-system. Finally we’ll look at what is required (using Go) to implement an Image based Operating System creation and deployment, and how they’ve been implemented into plunder.
Getting an Operating System deployed
Most Operating Systems are deployed in relatively the same manner:
A machine boots and reads from installation media (presented locally or over the network)
The target disks are prepared, typically partitions may be created or HA technologies such as disk mirroring and then finally these partitions are “formatted” so that they contain a file system.
Either a minimal set of packages or a custom selection of packages will be installed to the new file system. Most Operating Systems or distributions have their own concept of “packages” but ultimately under the covers the package contains binaries and required libraries for an application along with some logic that dictates where the files should be written too along with some versioning information that the package manager can use.
There may be some final customisation such as setting users, network configuration etc..
A Boot loader is written to the target disk so that when the machine is next powered on it can boot the newly provisioned Operating System.
The order of the steps may differ but pretty much all of the major Operating Systems (Linux, Windows, MacOS) follow the same pattern to deploy on target hardware.
Options for automating a deployment
There are usually two trains of thought when thinking about deploying an Operating System, which are scripted which will go through the steps listed above but no user interaction is required or image based which takes a copy of a deployment and uses that as a “rubber stamp” for other installs.
Scripted
Operating Systems were originally designed to be ran on hardware of a predetermined configuration, which meant that there was no need for customising of the installation. However as time passed a few things happened that suddenly required Operating Systems to become more flexible:
Usage of computers sky rocketed
The number of hardware vendors producing compute parts increased
A lot of traditional types of work became digitised.
All of these factors suddenly required an Operating System to support more and more types of hardware and it’s required configuration(s), furthermore end-users required the capability to tailor an Operating System to behave as needed. To provide this functionality Operating System vendors built rudimentary user interfaces that would ask questions or provide the capability for a user installing the OS to set various configuration options. This worked for a period of time but as more and more computer systems were deployed this became an administrative nightmare, as it was impossible to automate multiple installations as they required interaction to proceed and finally the need for humans to interact brings about the possibility of human error (Pesky humans) during the deployment.
In order for large scale IT system installations to take place then operations needed a method for unattended installations, where installations can happen without any involvement. The technique for this to work was to modify the Operating System installation code so that it could take a file that can answer all of the questions that would have previously required user input in order to progress the installation. These technologies are all named in a way that reflects that:
preeseed
answer file(s)
kickstart
jumpstart
Once a member of the operations team has “designed” the set of responses for their chosen Operating System then this single configuration can be re-used as many times as required. This removes the human element from accidentally entering the wrong data or clicking the wrong button during an Operating System installation and ensures that the installation is standardised and “documented”.
However, one thing to consider is that although a scripted installation is a repeatable procedure that requires no human interaction it is not always 100% reliable. This installation still runs through a lot of steps, such as every package has to be installed along with the prerequisite package management along with configuring devices and other things that happen during that initial installation phase. Whilst this may work perfectly on the initial machine undiscovered errors can appear when moving this installation method to different hardware. There have been numerous issues caused by packages relying on sleep during an installation step, the problem here usually is due to this package being developed on a laptop and then moved to much larger hardware. Suddenly this sleep is no longer in step with the behaviour of the hardware as the task completes much quicker than it had on slower hardware. This has typically led to numerous installation failures and can be thought of as a race-condition.
Image
Creating an image of an existing Operating System has existed for a long time, we can see it referenced in this 1960s IBM manual for their mainframes.
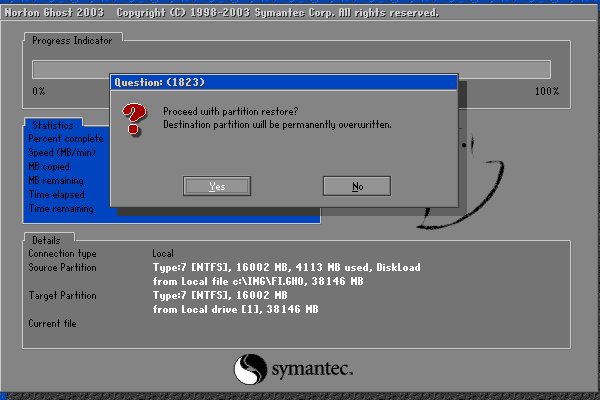
Shoutout for Norton Ghost !!
I have covered image based deployments, but my (google) research show ghost (1998) pre-dates Preseed/DebianInstaller (2004) and Kickstart(RHEL in 2000) and even Sun Microsystems with jumpstart (earliest mention I can find is Solaris 2.8 which is 1999).
Anatomy of a disk
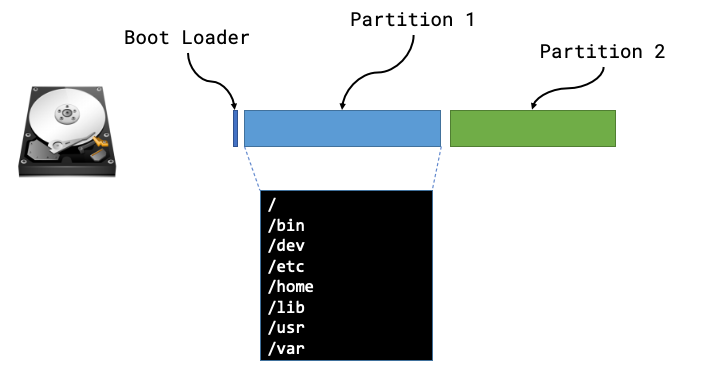
We can usually think of a disk being like a long strip of paper starting at position 0 and ending with the length of the strip of paper (or its capacity). The positions are vitally important as they’re used by a computer when it starts in order to find things on disk.
The Boot sector is the first place a machine will attempt to boot from once it has completed its hardware initialisation and hardware checks the code in this location will be used in order to instruct the computer where to look for the rest of the boot sequence and code. In the majority of examples a computer will boot the first phase from this boot sector and then be told where to look for the subsequent phases and more than likely the remaining code will live within a partition.
A partition defines some ring-fenced capacity on an underlying device that can be then presented to the underlying hardware as usable storage. Partitions will then be “formatted” so that they have a structure that understands concepts such as folders/directories and files, along with additional functionality such as permissions.
Now that we know the makeup of a disk we can see that there are lots of different things that we may need to be aware of, such as type of boot loader, size or number of partitions, type of file systems and then the files and packages that need installing within those partitions.
We can safely move away from all of this by taking a full copy of the disk! Starting from position 0 we can read every byte until we’ve reached the end of the disk (EOF) and we have a full copy of everything from boot loaders to partitions and the underlying files.
The steps for creating and using a machine image are usually:
Install an Operating System once (correctly)
Create an image of this deployed Operating System
Deploy the “golden image” to all other hosts
Concepts for managing OS images
The concept for reading/writing OS images consists of a number of basic actions:
Reading or Writing to a storage device e.g. /dev/sda
A source image (either copied from a deployed system or generated elsewhere)
A destination for the date from the cloned system, when reading from a deployed system we need to store a copy of the data somewhere
In relation to the final point, there have been numerous options to capture the contents of an existing system over time:
Mainframes could clone the system to tape
Earlier “modern” systems would/could clone to a series of Floppy disks and later on CD-ROM media
Stream the contents of a storage device over the network to a remote listening server.
Reading (cloning) data from a storage device
When capturing from an existing system, especially when this OS image will be used to deploy else where, there are a few things that need to be considered about the state of the source system.
Firstly it is ideal that it is as “clean” as possible, which typically means that the OS is deployed and any required POST-configuration and nothing else. If a system has been up for time or has been used then the filesystem could already be dirty through excess logs or files generated that will clutter the source image and end up being deployed through to all destination servers. We may want to consider removing or zeroing the contents of swap partitions or files as well to ensure nothing is taken from the source and passed to destination machines that doesn’t need to be copied.
Secondly that the disk isn’t actually being used when we want to clone or image its contents, whilst technically possible if the Operating System is busy reading and writing whilst we attempt to copy the underlying storage we will end up with files that could be half-written to or ultimately corrupt. We can boot from alternative media (USB/CD-ROM/Alternate Disk/Network) in order to leave our source disk un-used, which will allow us to copy it’s contents in a completely stable state.
Once we’ve started up our cloning tooling we only need to read all date from the underlying storage device to a secondary data store. We need to be aware that even if we’ve only installed a small amount of data as part of the Operating System our cloned copy will be the exact size of the underling storage device. e.g. a 100GB disk that is installed with a basic Ubuntu 18.04 package set (900MB) will still result in a 100GB OS Image.
Writing an OS Image to a destination device
As with reading the contents of an underlying storage device we can’t (or I certainly wouldn’t recommend) trying to use the same storage device at the same time as writing too it. If you had an existing system running an Operating System such as Win10 and we used some tooling to re-write our ubuntu disk image to the same storage then well …
To circumvent this issue we would need to start our destination machine from another medium such as another storage device leaving our destination device alone until we’re ready to write our destination disk image to this storage.
Finally we also need to consider the sizes of the disk image and the destination storage:
If our destination storage is smaller than the disk image then our writing of the image will fail. However, the system may start afterwards as the main contents of the Operating System has fit on the storage device. This can lead to an unstable state as the filesystem and partitions have logical boundaries that exist well beyond the capacity of the destination disk.
On the other hand if we write a 10GB OS image to a 100GB physical storage device then the remaining 90GB is left unused without some additional steps, typically involving first growing the partition to occupy the remaining 90GB of space and then growing the filesystem so it is aware of this additional capacity.
Writing your own OS imaging software
This section will detail the design around software I wrote to accomplish all of the things I’ve discussed above. All of the code samples are written in Go and the source code for the project can be found on the BOOTy repository.
It will be in three parts:
First, creating a boot environment that allows us to safely read/write from underlying storage
Second, Reading and Writing from underlying storage
Finally, post steps.
A solution for a clean environment
To ensure we can make a clean read or write to a storage device we need to ensure that it’s not being used at the time, so we will need to boot from a different environment that has our tooling in it.
Simplest option
We can simply use a live-CD image that allow us to boot a fully fledged Operating System, from here we can use some tooling like dd to take a copy of contents of the storage. The problems with this solution are that we can’t really automate this procedure and we will need a writeable location for the contents of the source disk.
Writing a custom Operating System
Phase one: LinuxKit
My initial plan was to do this with LinuxKit, where the code to handle the reading and writing of the underlying storage would live within a container and I would then use LinuxKit to bake this into a custom Linux distribution that I could then start on remote hosts.
Start remote host and point to our LinuxKit OS
Start Linux Kernel
Kernel boots, finds all hardware (including our storage device(s)
LinuxKit starts /init which in turn will start our application container
The container will then interact with the underlying storage device (e.g. write an image to the disk)
This solution was quick and easy to write, however a few issues:
Ensuring console output of what is transpiring
Stable rebooting or restarting of the host
Dropping to a console if a write fails
So whilst it did work, I decided I could probably do something a little smaller
Phase two: initramfs
This design uses two pieces of technology, mainly a Linux Kernel and an initramfs which is where the second stage of Linux Booting occurs, if we use the same chronology as above this design would look like the following:
Start remote host and point to our OS
Start Linux Kernel
Kernel boots, finds all hardware (including our storage device(s)
Kernel starts /init within our initramfs , this init is our code to manage underlying storage.
At this point our init is the only process started by the kernel and all work is performed within our init binary. Within our initramfs we can add in any additional binaries, such as a shell (busybox) or Logical Volume Manager tooling to manipulate disks (more on this later).
In order for this tooling to work our custom init will need to “setup” the environment so that various things exist within the Linux filesystem, including special device nodes such as /dev/tty or /dev/random which are required for things like writing console output or generating UUIDs for filesystems etc..
Below is the example code that we will need to generate our environment:
1 2 3 4 5 6 7 8 9 10 11 12 13
package main
import "syscall"
func main() {
// Mount /dev err := syscall.Mount("devtmpfs", "/dev", "devtmpfs", syscall.MS_MGC_VAL, 0)
We will need to mount various additional file systems in order for additional functionality to work as expected, mainly systems such as /proc(proc) and /sys (sysfs).
Once our environment is up and running, we will need to use dhcp in order to get an address on the network. There are numerous libraries available that provide DHCP client functionality and we can leverage one to run in a go routine to ensure we have an address and renew it if we get close to our lease expiring before we finish our work.
At this point we would do our disk image work, this will be covered next !
With an init we need to handle failure carefully, if our init process just ends either successfully 0 or with failure -1 then our kernel will simply panic. This means that we need to ensure we handle all errors carefully and in the event something fails ensure it is captured on screen (with a delay long enough for the error to be read) and then issue a command to either start a shell or reboot the host.
On error and we want to drop to a shell then the following code will ensure that the interrupt is passed from our init process to its children.
1 2 3 4 5 6 7 8 9 10 11 12
// TTY hack to support ctrl+c cmd := exec.Command("/usr/bin/setsid", "cttyhack", "/bin/sh") cmd.Stdin, cmd.Stdout, cmd.Stderr = os.Stdin, os.Stdout, os.Stderr
Finally instead of simply ending our init process we will need to issue a reboot or shutdown as simply ending init will result in a kernel panic and a hung system.
Note: Before doing this ensure that disk operations are complete and that anything mounted or open has been closed and unmounted, as this syscall will immediately reboot.
1 2 3 4 5 6 7 8
err := syscall.Reboot(syscall.LINUX_REBOOT_CMD_RESTART) if err != nil { log.Errorf("reboot off failed: %v", err) Shell() }
// We can opt to panic by doing the following os.Exit(1)
We now have all of the required bits in place:
Our custom /init starts up
The relevant paths are created or mounted
Any devices nodes are created allowing us to interact with the system as a whole
We use a DHCP Client to retrieve an address on the network
In the event of an error we can start a shell process allowing us to examine further as to what the error may be
Finally we will issue a reboot syscall when we’ve finished
Managing images, and storage devices
With the above /init in place we can now boot a system that has all the underlying devices ready, is present on the network and in event of errors can either restart or drop to a point where we can look into debugging.
We are in a position where we can put together some code that will allow reading the storage and sending it across the network to a remote server OR pull that same data and write it to the underlying storage.
Identifying the server and behaviour
In order to know what action a server should take when it is booted from our custom init we need to use a unique identifier, luckily we have one that is built into every machine its MAC/Hardware address.
1 2 3 4 5 6 7 8
// Get the mac address of the interface ifname (in our case "eth0") mac, err := net.InterfaceByName(ifname) if err != nil { return "", err }
// Convert into something that RFC 3986 compliant return strings.Replace(mac, ":", "-", -1)
The above piece of code will find the MAC address of an interface passed as ifname and it will then convert that into a string that is a compliant URI string 00:11:22:33:44:55 -> 00-11-22-33-44-55 . We can now use this to build a url that we can request to find out what action we should be performing, so once init is ready it will build this configuration and perform a GET on http://<serverURL>/<MAC address>.
You may be wondering where we specify the <serverURL> address, well we can hard code this into our init alternatively we can pass this on boot as a flag to the kernel MYURL=http://192.168.0.1, this will appear as a environment variable within our newly started Operating System.
1
serverURL := os.Getenv("MYURL")
Reading and Writing
We can now call back to a server that will can inform the init process if it should be reading from the storage device and creating an OS image or pulling an image and writing it to a device.
Writing an image to disk
This is arguably the easier task as we can use a number of pre-existing features within Go to make this very straight forward. Once we’ve been told from the server that we’re writing an image, we should also be given a URL that points to an OS image location. We can pass this imageURL to our writing function and use an io.Copy() to write/stream this image directly to the underlying storage.
// Open the underlying storage diskIn, err := os.OpenFile("/dev/sda", os.O_CREATE|os.O_WRONLY, 0644) if err != nil { return err }
// Read from resp.Body and Write to the underlying Storage count, err := io.Copy(diskIn, resp.Body) if err != nil { return fmt.Errorf("Error writing %d bytes to disk [%s] -> %v", count, destinationDevice, err) }
Reading from Disk to an Image
The main issue we hit with reading from a disk to a remote location is around the large amounts of data, the underlying storage could easily be many many GBs of data that would need transmitting to a remote server. In order to send such large amounts of data over the HTTP protocol we can use a multipart writer that will break up the file and rebuild it on the server side. To do this we create a multipart writer and then as we read chunks of data from /dev/sda we send them as multiple parts over the network.
// Go routine for the copy operation go func() { defer close(errchan) defer writer.Close() defer mwriter.Close()
// imageKey is the key that the client will look for and // key is the what the file should be called, we can set this to teh MAC address of the host w, err := mwriter.CreateFormFile("imageKey", key) if err != nil { errchan <- err return }
// Open the underlying storage diskIn, err := os.Open("/dev/sda") if err != nil { errchan <- err return }
// Copy from the disk into the mulitpart writer (which inturn sends data over the network) if written, err := io.Copy(w, diskIn); err != nil { errchan <- fmt.Errorf("error copying %s (%d bytes written): %v", path, written, err) return } }
resp, err := client.Do(req) merr := <-errchan
if err != nil || merr != nil { return resp, fmt.Errorf("http error: %v, multipart error: %v", err, merr) }
Shrinking Images
Using disk images can be incredibly wasteful when thinking about network traffic, a 1GB Operating System on a 100GB disk requires sending 100GB of data (even when most of the disk is probably zeros). To save a lot of space we can expand our read/write functions so that we pass our data through a compressor (or expander in the other direction), we can do this very easily by modifying the above code examples.
// Reading raw data from Disk, compressing it and sending it over the network zipWriter := gzip.NewWriter(w) if err != nil { errchan <- fmt.Errorf("[ERROR] New gzip reader: %s", err) return }
// run an io.Copy on the disk into the zipWriter if written, err := io.Copy(zipWriter, diskIn); err != nil { errchan <- fmt.Errorf("error copying %s (%d bytes written): %v", path, written, err) return }
// Ensure we close our zipWriter (otherwise we will get "unexpected EOF") err = zipWriter.Close()
// Expanding compressed data and writing it to Disk
// Create a gzip reader that takes the compressed data over the network zipOUT, err := gzip.NewReader(resp.Body) if err != nil { fmt.Println("[ERROR] New gzip reader:", err) } defer zipOUT.Close()
// Read uncompressed data from gzip Reader and Write to the underlying Storage count, err := io.Copy(fileOut, zipOUT) if err != nil { return fmt.Errorf("Error writing %d bytes to disk [%s] -> %v", count, destinationDevice, err) }
We can see that we simply “man-in-the-middle” a compression solution that slots straight into the existing workflow that was shown earlier. The results of adding in compression are clear to see when taking an Ubuntu 18.04 standard install on any sized disk 4GB / 100GB the compressed OS Image is always around 900MB.
Tidying up
We could simply stop here and we have all of the components in place to both create and write Operating System images to various hardware over the network, however in a lot of cases we may want to perform some POST configuration once we’ve deployed an image.
Grow the storage
To perform this we (in most circumstances) require some external tooling, if our base Operating System image used technologies like LVM etc.. then we’ll need additional tooling to interact with them. So within our initramfs we may want to create a static build of LVM2 so that we can use this tooling without requiring a large amount of additional libraries within our RAM disk. One other technique we can use is to make use of tooling that may exist within the Operating System Image that we’ve just written to disk, below is a sample workflow:
Write Operating System image to /dev/sda
Exec out to /usr/sbin/partprobe within out ram-disk to scan /dev/sda and find our newly written disk contents
Exec out to /sbin/lvm to enable any logical volumes TODO: look at BLKRRPART to replace partprobe
At this point our /init will have an update /dev that will have any partitions (/dev/sda1) or logical volumes (/dev/ubuntu-vg/root) present at which point we can act on these partitions to grow them and their filesystems.
Some cheeky chroot manuveurs
As mentioned we can use a workflow that means we can use the tooling that exists within our newly deployed Operating System instead of filling our ramdisk with additional tooling and the associated dependencies.
The following workflow will grow a 900MB image written to a 20GB disk that uses LVM:
Mount the root volume inside the ram-disk /dev/ubuntu-vg/root -> /mnt
Use chroot to pretend we’re inside the newly deployed Operating System grow the underlying partition chroot /mnt /usr/bin/growpart /dev/sda 1
Again chroot and update LVM to see the newly grown disk chroot /mnt /sbin/pvresize /dev/sda1
Finally grow the filesystem within the logical volume chroot /mnt /sbin/resize2fs /dev/ubuntu-vg/root
Finally, unmount the logical volume ensuring that any writes are flushed!
Configure networking and other things
The above workflow for growing the storage mounts our newly provisioned disk image, once we’ve finished growing the disk/partitions and filesystem we have the opportunity to do additional post-deployment steps. For networking this could include writing a static networking configuration given too us from the provisioning server to the underlying filesystem before we unmount it and boot from it.
Overview
In this post we have detailed some of the deployment technologies that exist in order to provision Operating Systems and we can appreciate that there are a number of options available to us about which approach can work best. We’ve also stepped through various code snippets that detail some of the functionality that has recently been added into plndr to add the capability to create and use OS images to quickly and efficiently deploy Operating Systems to bare-metal (and virtualised) servers.
All of the source code samples came from BOOTy which is a project to build an initramfs that can perform a call back to a plndr server to find out it’s course of action.
Any questions, mistakes or corrections either add in the comments or hit me up on twitter -> thebsdbox
This post will detail a number of (I think at least) awesome use-cases for client-go. Some of these are use-cases that are similar or may almost be identical to the examples that already exist, but with some additional text that details what some of these terms actually mean and when it makes sense to use them.
Why Client-Go?
Kubernetes exposes everything through an API (all managed by the active API server) from the control-plane, the API is rest based and is the sole way of controlling the a cluster. This means that things like CI/CD pipelines, various dashboards and even kubectl will all use the API through an endpoint (network address) with the credentials (key) in order communicate with a cluster.
As this is just a standard REST over http(s) then there are a myriad of methods that can be used in order to communicate with the Kubernetes API. We can demonstrate this in a quick example:
Check health of Kubernetes API
1 2
$ curl -k https://control-plane01:6443/healthz ok
The above example is an endpoint that requires no authentication, however if we try to use another endpoint without the correct authentication we’ll receive something like the following:
Note: Under most circumstances the authentication a user would need to speak with a cluster will live within a $home/.kube/config file. Tooling like kubectl will automatically look for this file in order to communicate with the API endpoint.
I wouldn’t recommend interacting with the raw endpoints as shown above, they’re mainly shown as an example of what is possible. To make life far simpler for developers to interact with the Kubernetes API then there are a number of wrappers/SDKs that provide:
Control and management of both the SDK <-> API versions
Language specific objects and methods to provide sane interfaces to Kubernetes objects
Helper functions for logging in and managing cluster access
(A plethora of additional features to make your life easier)
As mentioned this post will cover client-go, but there are numerous SDKs in various languages that are covered in varying levels of detail here.
Accessing a cluster, either In-Cluster or Outside cluster
This can be confusing for the first time an end-user will attempt to authenticate with a cluster using client-go.
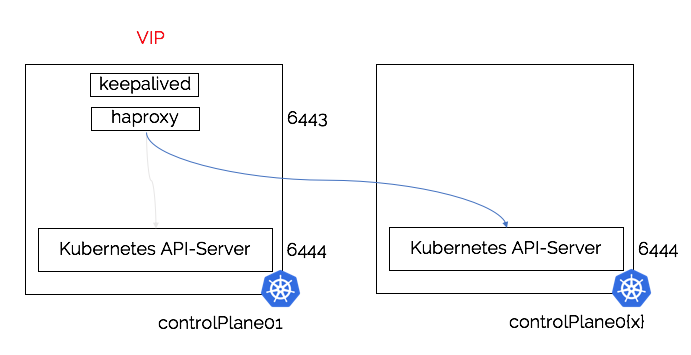
Whilst working on a number of kubernetes control-plane deployments and the fighting with kubeadm and components like haproxy, nginx and keepalived, I decided to try and create my own load-balancer. In the end this proved to be not too complicated to replicate both a Virtual IP and load-balancing over the backends (master nodes) with the standard Go packages. That project now is pretty stable and can easily be used to create a HA control-plane, all of that can be found on https://kube-vip.io. The next thing I wanted to try (and I’ve been considering learning about this for a while) was creating a load-balancer “within” Kubernetes, as in provide the capability and functionality to kubectl expose <...> --type=LoadBalancer. It turns out that in order to provide this functionality within Kubernetes you need to write a Cloud Provider that the Kubernetes Cloud Controller Manager can interface with.
This post will “chronicle” the process for doing that… :-D
Kubernetes Cloud Providers
We will start with the obvious question.
What are Cloud providers?
Out of the box Kubernetes can’t really do a great deal, it really needs a lot of components to sit on top of or to interface with in order for it to provide the capability to run workloads. For example even in a basic Kubernetes cluster there is a requirement to have a container runtime (CRI, Container Runtime Interface) in order to execute the container, then we would need a networking plugin (CNI, Container Network Interface) in order to provide networking within the cluster.
On the flip side, a typical cloud company (AWS, GCloud, Azure etc…) offers a plethora of cool features and functionality that it would be awesome to consume through the Kubernetes cluster:
Load Balancers
Cloud instances (VMs, in some placess bare-metal)
Areas/zones
Deep API integrations into the infrastructure
So how do we marry up these two platforms to share that functionality …
.. Kubernetes Cloud Providers ..
Using Cloud providers
In most circumstances, you won’t even know that you’re using a cloud provider (which I suppose is kind of the point) and only when you try to create an object that the cloud provide can create/manage/delete will it actually be invoked.
The most common use-case (and the one this post is focussing on) is the creation of a load balancer within Kubernetes and it’s “counterpart” being provided by the cloud vendor. In the case of the cloud vendor Amazon Web Services (AWS) then creating a services type: LoadBalancer will create an Elastic Load Balancer (ELB) that will then load balance traffic over the selected pods. All of this functionality from the Cloud Provider Interface abstracts away the underlying technology and regardless of where a cluster is running a LoadBalancer just becomes a LoadBalancer.
Creating a Cloud Provider!
So now onto the actual steps to creating your own cloud provider, this is all going to be written in Go and I’ll do my best to be as descriptive as possible.
Wait, what is the cloud-controller-manager?
In Kubernetes v1.6 the original design was that all the cloud providers would have their vendor specific code all live in the same place. This ultimately lead to a point where all Kubernetes clusters came with a large cloud-controller-manager that at startup would be told which vendor code path to run down.
These were originally called In Tree cloud providers and there has been a push over the last few years to move to Out of Tree providers. When deploying a Kubernetes cluster the only change is that instead of starting the cloud-controller-manager with a specific vendor path (e.g. vsphere or aws), the operator would deploy the vendor specific cloud-provider such as cloud-provider-aws.
A Note about the “why” of In Tree / Out of Tree
There has been a shift of stripping code and “vendor specific” functionality from the main Kubernetes source repositories and into their own repositories. The main reasons for this:
Removes a tight-coupling between external/vendor code and Kubernetes proper
Allowed these projects to move at a different release rate to the main project
Slims the Kubernetes code base and allows these things to become optional
Reduces the vulnerability footprint of vendor code within the Kubernetes project
The interfaces ensure ongoing compatibility for these Out Of Tree projects
So for someone to create their own cloud provider they will need to follow a standard that was set by the original cloud-controller-manager, this standard is exposed through method sets and interfaces which can be read about more here.
tl;dr simply put, the cloud-controller-manager sets a standard that means if I want to expose a Load Balancer service it needs to also expose a number of methods (with matching signature). We can further see in the LoadBalancer interface here all of the functions that my Loadbalancer must expose in order to work.
The interface
The interface for a cloud-provider can be viewed here, we can see that this interface provides a number of functions that will return the interface for a specific type of functionality.
The more common interfaces I’ve summarised below:
Instances controller - responsible for updating kubernetes nodes using cloud APIs and deleting kubernetes nodes that were deleted on your cloud.
LoadBalancers controller - responsible for load balancers on your cloud against services of type: LoadBalancer.
Routes controller - responsible for setting up network routes on your cloud
Example provider (code) cloud-provider-thebsdbox
This section will cover in Go code all of the basics for building a cloud-provider that will handle all of the services requests (that are type: LoadBalancer). When implementing your own, ensure you use correct paths and package names!
This struct{} contains our vendor specific implementations of functionality, such as load-balancers, instances etc..
1 2 3
type ThebsdboxCloudProvider struct { lb cloudprovider.LoadBalancer }
We’re only defining a loadbalancer lb variable as part of our cloud-provider instances as this is the only functionality our provider will expose.
init()
This function will mean that before our cloud-provider actually starts (before the main() function is called) we will register our vendor specific cloud-provider. It will also ensure that our newly registered cloud-provider will be instantiated with the newThebsdboxCloudProvider function.
When our cloud-provider actually has started (the main() function has been called) the cloud-provider controller will look at all registered providers, and it will find ours that we registered in the init() function. It will then call our instantiation function newLoadBalancer(), which will do any pre-tasks for setting up our load balancer, it will then assign it to lb.
This function is pretty much the crux of enabling the load balancer functionality and as part of the cloud-controller-manager spec defines what functionality our cloud-provider will expose. These functions will return one of two things:
Our instantiated functionality (in this case our loadbalancer object, returned as lb)
If this is enabled or not (true/false)
Everything that we’re not exposing from our cloud-provider will return false and can be seen in the disabled.go source.
disabled.go
All of these functions disable these bits of functionality within our cloud-provider
// Instances returns an instances interface. Also returns true if the interface is supported, false otherwise. func (t *ThebsdboxCloudProvider) Instances() (cloudprovider.Instances, bool) { return nil, false }
// Zones returns a zones interface. Also returns true if the interface is supported, false otherwise. func (t *ThebsdboxCloudProvider) Zones() (cloudprovider.Zones, bool) { return nil, false }
// Clusters returns a clusters interface. Also returns true if the interface is supported, false otherwise. func (t *ThebsdboxCloudProvider) Clusters() (cloudprovider.Clusters, bool) { return nil, false }
// Routes returns a routes interface along with whether the interface is supported. func (t *ThebsdboxCloudProvider) Routes() (cloudprovider.Routes, bool) { return nil, false }
// HasClusterID provides an opportunity for cloud-provider-specific code to process DNS settings for pods. func (t *ThebsdboxCloudProvider) HasClusterID() bool { return false }
loadbalancer.go
Our LoadBalancer source code again has to match the interface as expressed here, we can see those functions defined below and exposed as methods as part of our thebsdboxLBManager struct.
func newLoadBalancer() cloudprovider.LoadBalancer { // Needs code to get a kubeclient => client // Needs code to get a namespace to operate in => namespace
// GetLoadBalancerName returns the name of the load balancer. Implementations must treat the // *v1.Service parameter as read-only and not modify it. func (tlb *thebsdboxLBManager) GetLoadBalancerName(_ context.Context, clusterName string, service *v1.Service) string { return getDefaultLoadBalancerName(service) }
This function is called when the cloud-provider itself is initialised and can be seen in cloud.go as part of the newThebsdboxCloudProvider() method. The newly created load balancer object once created is then added to the cloud-providers main object for use when needed.
Interface methods
EnsureLoadBalancer
Creates a LoadBalancer if one didn’t exist to begin with and then return it’s status (with the load balancer address)
UpdateLoadBalancer
Updates an existing LoadBalancer, or will create one if it didn’t exist and then return it’s status (with the load balancer address)
EnsureLoadBalancerDeleted
Calls GetLoadBalancer first to ensure that the load balancer exists, and if so it will delete the vendor specific load balancer. If this completes successfully then the service of type: LoadBalancer is removed as an object within Kubernetes.
GetLoadBalancer
This will speak natively to the vendor specific load balancer to make sure that it has been provisioned correctly.
GetLoadBalancerName
Returns the name of the load balancer instance.
main.go
This is a the standard main.go as given by the actual cloud-controller-manager example. The one change is the addition of our // OUR CLOUD PROVIDER which adds all of our vendor specific cloud-provider methods.
init() in cloud.go is called and registers our cloud-provider and the call back to our newCloudProvider() method.
The command.Execute() in main.go starts the cloud-controller-manager
The cloud-controller-manager method will look at all of the registered cloud-providers and find our registered provider.
Our provider will have its newCloudProvider() method called which sets up everything that is needed for it to be able to complete it’s tasks.
Our cloud provider is now running, when a user tries to create a resource that we’ve registered for (Load Balancers) our vendor code will be called to provide this functionality.
_ “k8s.io/component-base/metrics/prometheus/version” // for version metric registration // NOTE: Importing all in-tree cloud-providers is not required when // implementing an out-of-tree cloud-provider. _ “k8s.io/component-base/metrics/prometheus/clientgo” // load all the prometheus client-go plugins _ “k8s.io/kubernetes/pkg/cloudprovider/providers”
Hopefully this is of some use as to how a Kubernetes cloud-provider is architected, to understand a few more examples I’ve included some other providers:
This post is relatively delayed due to laziness “business reasons”, also the last post about bare-metal Kubernetes deployments took too long.
A lot of people on the twitter sphere published a decade and/or a year in review.. so I’ve raided my iCloud photo library and will attempt to put something together.
Pre-2009
Added this in because it’s relevant to where I found myself ending up in 2009..
So prior to 2009 I had been through a couple of support roles, being a DB admin and running a support team of Linux/UNIX, Windows, DBs and backup engineers inside a (B)ritish (T)elecommunications company. Following this I became a consolidation architect with Sun Microsystems (/me pours one out for SUN), with the project goal of shrinking five creaking old data centres into a shiny brand new one for the same (B)ritish (T)elecommunications company. The main goal was taking their big old servers (E10Ks, V440s etc..) and migrating their applications into Solaris Zones.
E10K with human for comparison
You might be thinking why does this matter, well somehow I’ve ended up doing the same thing over ten years later ¯\_(ツ)_/¯
Back to the timeline, Towards the end of 2008 things took a pretty grim turn and the financial crash caused a 50 person team (In September) to be down to 4 people by November at which point it became a 3 person team (me being the 4th person 😔).
2009
In mid-January I had been out of work for three months, the financial crash combined with the Christmas period meant that the job market was pretty much none-existent. I think we had enough money for a month or two of rent for where we were living and then that would be it 😐…
Then finally a random recruitment email appeared (which I was surprised to find that I still have it in my gmail😀)
1 2 3 4 5 6
Hello Daniel,
Would you be interested in a permanent role with the European Space Agency based in Frankfurt?
Regards
A number of interviews later I accepted the role, packed bags, booked flight to Frankfurt … and then got the bus to Darmstadt
So not actually Frankfurt after all
The European Space Agency (ESOC - Space Operations Centre) 2009-2012
I spent four crazy years living in Germany where I made a ton of friends from all over the world (Australia, Indonesia, Bulgaria, Italy, America, Spain, Greece and of course Germany). From a social perspective Germany has a fantastic outdoor lifestyle:
Endless wine and beer festivals
Dedicated cycling lanes and walking routes throughout the countryside
Excellent weather for lazy evenings
Cafes and restaurants have a focus chilling outdoors
Towards the end of the year it’s the autumn festivals and then the Christmas markets
Did I mention the beer festivals?
The work itself was pretty varied, sometimes a focus on writing reams of paperwork (100+ page guide to installing SuSE 🙄) to architecting and building platforms and systems for actual space missions. Also there was the opportunity to support some of the actual satellite missions which was always both exciting and pretty terrifying be part of.
Everyone terrifying witness the ATV (automated telemetry vehicle) dock un-assisted with ISS
Before we modernised the command centre
All brand new, (still powered by some of my hacky kernel modules)
Back to UK, SKY 2012-2014
With Kim unable really to find the role that made sense for her, we made the decision to head back to the UK as the market had started to improve. I took a role with Sky that was involved some of the heaviest infrastructure work I’ve ever been part of, but a fantastic experience none-the-less. Deploying a Disaster recovery site almost single handedly was a highlight! (Ah site B) Everything from Servers(HPE/Cisco with vSphere), to networking (Cisco Nexus switches) and storage (EMC/IBM XiV/Brocade) I got to play with and learn about. I also had the opportunity to decommission the original site, which was also fun and also a little bit on the gross side… When your cabling is “organically” grown it ultimately becomes an unfathomable under the floor mess for someone else (me) to sort out.
This took days to sort out
Suits, travel and presenting, HPE 2014 - 2017
By now Kims career had taken off, I’d spent a fantastic few years getting pretty low-level with various infrastructure vendors when one reached out to me. Approximately 48 interviews later on I’d bought a suit (mandatory) and was part of a team in HPE focussed on the merits of “converged infrastructure”!
I certainly did not choose the title on this 🙄
Over the three to four years at HPE I created a lot of powerpoint, learnt a great deal about PCI-E switching ¯\_(ツ)_/¯, memristors and a variety of other technologies. I was more than a little insecure about being the only person on the team without several CCIE certifications amongst other various industry accolades, however the entire team was 110% focussed on knowledge sharing and ensuring we all learnt from one another as much as possible (something I’m passionate about). It was here that I was asked to present in-front of an audience for the first time, which I still have nightmares about too this day… standing on stage shaking and stumbling over my words whilst trying to remember all my content about “sustainable data centre energy use” 😬. Although somehow after getting through that presentation I ended up being drafted to present more and more, to the point where I was regularly travelling around doing roadshows about various new HPE products. At some point I was asked to work on a new HPE partnership with a start up called Docker 🐳…
As part of some of the work I’d been doing at HPE around automating bare-metal, I’d stumbled across a project called Docker InfraKit and had written a plugin so that it could be extended to automate HPEs converged infrastructure. This lead to a chance email from an employee at Docker that asked if I’d be interested in participating in another project they were developing. I immediately said “yes” as it sounded super exciting to be part of! I received an email invite to a private GitHub repository to discover a new project for building Linux distributions .. to my horror the entire project was written in GO (I’d never written a single line of GO code at this point) 😱
Too embarrassed to say anything I decided to try and quickly get up to speed, I quietly worked away on simple fixes to command line flags and updating documentation. Finally I managed to write some code that “worked” and allowed the tool to build Linux images as VMDK files and run them in VMware Fusion and vSphere clusters.
A random start to a startup, Docker 2017 - 2018
Whilst still at HPE I went to DockerCon US 2017 in Austin, which turned out to be a very bonkers experience…
I had the privilege of joining the Docker Captains program, which is a group of people that are ambassadors around all things Docker.
I got to see the project I’d become part of finally be renamed (Moby -> LinuxKit) and be released to the wider community!
I made some amazing friends at Docker including Betty and Scott, amongst others :-)
Also getting to hang around with Solomon was great fun :-)
Whilst also in Austin I was asked to join the Docker team 🐳😀
Helping customers around EMEA successfully deploy Containers and clusters, also how to migrate their applications correctly
Building a modern app migration strategy for to Docker Enterprise Edition
36 hours in Seattle, vHeptio 2018 - now
Toward the end of the 18 months the changes in strategy had started to push me to consider other options, and after a “chance” meeting with Scott Lowe in a coffee shop in San Francisco I decided to go have a real conversation with Heptio (I’d also had a conversation with $current_employer but that’s another story). I flew from the UK to spend a day and a half in Seattle to speak with Heptio, I pretty much spent the same amount of time in airports and planes as I did in Seattle itself but it was worth it.
The Seattle Space Needle
Seattle has some amazing buildings
After accepting I became the sole “field engineer” in EMEA and ended up fiddling with, breaking and fixing Kubernetes clusters for a living :-)
Heptio was acquired by VMware in early 2019, and we’ve largely been continuing the same work.. The only change is that I’m now no longer the only person in EMEA 😀
Undeterred by the memes and “thought leadership” I decided I’d finally complete this architectural overview of deploying Kubernetes on bare-metal.
To begin with we need to fix the naming.. no-one has ever deployed Kubernetes on bare-metal. You deploy Kubernetes on an Operating System, that OS can be installed on bare-metal hardware or virtual hardware etc.. (moving on).
This post ended up sprawling on much further than I ever really intended it to, so It’s broken into four main sections:
Why would I bother with bare-metal in the first place?
What does the operating environment look like, i.e. what do I get to build my cluster with?
Architectural decisions and designs when deploying a cluster on bare-metal
Actual steps to deploy the cluster… (probably what most people would care about)
One other assumption that this post takes when considering bare-metal is that the we’re typically in an on-premise environment or in an environment that doesn’t present any existing services so everything will need to be created to build the HA cluster. For further clarification about what bare-metal means you can start here
So lets begin!
Why Bare-Metal?
After having a colleague read through a draft of this post, his immediate thoughts were:
“I’m left feeling a bit ‘why would I do this’ 🙂”
It turned out that I’d not really given any actual positive reasons for running Kubernetes on Bare-Metal… So why would anyone go to the trouble?
Control
If we’re not building our Kubernetes clusters on bare-metal, then typically we’re building them in “the cloud” !
If that is the case then we typically will be presented with two options to deploy our clusters:
Managed as a service (KaaS/CaaS or whatever marketing call it these days), but effectively the cloud provider architects and owns the cluster architecture and you get access to deployed solution.
DIY, virtual hardware + virtual networking followed by a bit of rolling up the sleeves and “hey-presto”!
Both of these options are fantastic and provide a solution if you need to move quick (KaaS) or need a degree of flexibility (DIY). Given that these two examples appear to cover most use-cases why should we care?
Well mainly control and customisation.. I’m not sure if it’s just me but anything that is a prebuilt “completed” solution warrants a desire to immediately deconstruct to understand, and customise to suit needs that I didn’t know that I had.
A lot of this can crop up in cloud environments, where architectural decisions around the entire cluster (KaaS) have already been decided and can’t be changed. This can also exist even in a DIY cluster in cloud environments, where virtual machines sizes or configurations are fixed limiting cluster flexibility. It can even extend to design decisions on networking functionality or technologies to limitations on scale.
Design / Architecture and Edge
This is tied to the above point, but it is still relevant to be called out as it’s own reason. One of the most common reasons for a bare-metal requirement is that the design and architecture requirements. Often the applications that are being migrated or being re-designed to “cloud-native” principles may need access to existing systems that can’t be changed or updated. Alternatively there may be a requirement on things like FPGAs or types of GPUs that simply aren’t available within alternative environments.
One other requirement that is starting to become more and more common are edge clusters, which are typically small on-site clusters that will handle local processes in things like stores, offices, warehouses etc.. and will send the results back to central processing once complete. In most use-cases the infrastructure can be 2-3 1U servers to a stack of Raspberry PIs, all driven by things like application needs and physical space and power.
Workloads
In a lot of scenarios running a “simple” workload on bare-metal versus within a cloud environment won’t look any different. However there will be a number of application workloads that will require bare-metal:
100% predictable performance that dictate no noisy neighbours or overhead
Custom or specific hardware: Crypto, GPUs or FPGAs
Data locality and/or local laws
Application network requirements or hard coded addresses
Operational team skillset (having to learn a cloud provider technology stack)
Security and locality
Some applications that process customer, financial or personal data may (by law) have requirements that dictate that all communication paths or compute locations have to be verifiable. Unfortunately the nebulous behaviour of the cloud means that in some cases it’s not possible at the time of an audit to reliably say where customer data is located. In these situations the most common strategy is to have both the data and processing work done in an owned or co-located datacenter that meets security and legal requirements.
Also with bare-metal the onus to provide security is on the bare-metal or infrastructure operators, allowing them to be as bleeding edge when it comes to patches and updates. This is true not just for the applications, the Kubernetes cluster and the Operating System but also the hardware devices such as server firmware and networking devices. With a cloud environment the underlying infrastructure vendors or it’s vulnerabilities isn’t always commonly disclosed, meaning that you’re at the mercy of the cloud provider to handle this level of patching and fixes.
Lock-in?
Finally, lock-in … I don’t work in sales so I don’t necessarily buy this as a reason. A “well” architected solution can negate a lot of the lock-in, however when things are rushed or you opt to deeply couple with too many cloud services then you can end up in a situation where you’re dependant on this functionality and at which point you may be technically locked in, with a lot of work required to un-pick and re-build this functionality elsewhere.
…
So, with all this in mind what do we have to work with in a typical bare-metal environment ?
Operating Environment
This section will have a brief overview of what is typically available to us in a bare-metal environment, again I typically will consider bare-metal a non-hypervisor on-premises environment.
Compute hardware
With a bare-metal deployment we usually mean installing software onto hardware with no hypervisor present. In some circumstances this may or may not provide better performance or save both money or reduce complexity.
However, if we take into consideration the size of a standard enterprise class server (TBs of ram, 10s of cores/CPUs) we can start to see that we have a huge amount of computing power restrained to a single instance of both Operating System and Kubernetes use-case (worker/control plane). If we just consider the Kubernetes use-case for control plane nodes (low memory and CPU) then bare-metal servers can immediately lead to hugely under-utilised hardware.
We also need to consider the actual deployment of the Operating system, which still relies on technologies that are ~20 years old. With virtualisation we can utilise templates and OS images to rapidly deploy a node on virtual hardware. With bare-metal we need to care about the physical hardware and either take a CD to the machine or aim to deploy using a remote method.
Load-balancing
A highly available Kubernetes cluster requires a load-balancer to provide availability to the control plane in the event a node fails and to balance the load into the control plane. In a cloud environment an end-user clicks the [load-balancer] button and * magic * occurs, followed by a virtual IP that an end user will access to provide both HA and load-balancing to nodes underneath it.
When thinking about a bare-metal on-premises environment we have only a handful of architectural options.
Hardware (appliance) Load Balancer
If budget allows then as part of the architecture we can use a pair of load balancer appliances. We will require a pair of them to provide redundancy incase the appliance fails or requires maintenance. These appliances will typically provide the capability to create an external virtual IP address that can load balance over a number of physical IP addresses.
In some circumstances the load-balancers may provide an API or capability to integrate their functionality into a Kubernetes cluster making it much easier for applications deployed within the cluster to utilise these hardware load balancers for application redundancy.
Software Load balancers
The alternative is to use a software based load balancer which are usually simple to deploy. However in order to provide both load-balancing and high-availability then we will have to implement additional software to sit along side the software load-balancers. These two pieces of functionality are:
Virtual IP address
This functionality provides the capability of having an externally accessible IP address that can move between functioning nodes. This means that users attempting to access a service will use this VIP (virtual IP), which will always be exposed on a functioning node.
Network Service (application) Load-balancing
Load-balancing provides two pieces of functionality, it provides high-availability by ensuring that traffic is directed to a working node. It also ensures that traffic can be shared between a pool of working nodes ensuring that load is balanced. This provides the capability of having a larger amount of available service capacity than a single host, that can be scaled up by increasing nodes in the pool.
With both of these pieces of functionality in place we have a single virtual IP that will always direct us to a working load-balancer instance, which in turn will load-balance our access to the network service we want to access.
Automation
The combination of {x}aaS and virtual machines both massively simplify or obscure a lot of the implementation work for deploying servers/services.
Going back to bare-metal we suddenly are back to a large amount of very old and very hard to automate pieces of work, which I’ve previously discussed here https://thebsdbox.co.uk/2019/12/08/The-alchemy-of-turning-bare-metal-into-a-cloud/. We will typically have to follow older installation methods to do the actual provisioning such as kickstart or preseed and only after this can we look at automation such as ansible to automate the deployment of Kubernetes.
Architectural choices
This section provides design decisions that need to be considered when deploying a highly-available Kubernetes cluster on bare-metal hardware and without cloud services. Using some of these design decisions can allow you to be both more efficient in the use of modern hardware and provide a lot of the same sorts of service that people come to expect from a cloud environment!
Nodes
Node sizing typically falls into two categories:
Control-plane node(s) scaled based upon how many workers will be managed, and how much additional API requests will be hitting the manager components
Worker node(s) scaled based upon the application requirements, often clusters will have more than one application running on them. So your capacity planning will need to ensure that all requirements are captured, along with sufficient multi-tenancy and node labelling where needed
I’ve been back and forth through https://kubernetes.io, looking for anything documents that explicitly say that a control-plane node should look like {x} but I’ve drawn a blank. In the end the only sizing I can actually find is within the documentation for kubeadm, which states:
Supported OS (ubuntu/centos etc..)
2 GB or more ram
2 CPUs
Connectivity
Try finding a server with those specs without a time machine to the year 2000. In a number of engagements that I’ve been part of have consisted of server farms all built from a pre-chosen server specification. Recently in one engagement I came across 2u servers with 2x24 cores and 512GB of ram as their standard build, this meant that this relatively small Kubernetes HA control plane was underutilising:
138 cores
1530 GB of ram
Power, cooling and support/maintenance …
What are the options for ring-fencing these control-plane nodes, to allow us to use the remaining capacity …
Virtualise control-plane only
This seems a bit like a cheat, but given the reasonably small requirements for the control-plane components it does make good sense to run the control-plane nodes as virtualised machines (with the adequate resources guaranteed). Regardless of hypervisor or vmm (virtual machine manager) typically a small amount of overhead is required for the emulation of physical hardware along with minuscule performance overheads on I/O. However the benefit of freeing the remaining capacity to be used for other use-cases hugely outweighs any tiny performance or virtualisation inefficiencies.
Kubernetes resource control
In a production environment the control-plane nodes should only be running the control-plane components. This means that anything application specific is only ran on the worker nodes. The main reason that this is a recommendation or usually a best-practice is mainly down to a few key reasons:
Security: Applications strive to be secure, however we can help security by keeping the running workloads separate to the control-plane
Management and Operations: Keeping application workloads separate allows easier and clearer monitoring of both the application and the infrastructure (node behaviour)
Stability: Applications can be end-user facing and sometimes subject to Attacks or denials of service, keeping them separate will ensure that the control-plane is unaffected by these events.
There are a number of options available to us that would allow some workloads to be safely ran next to the control-plane components. All of these would involve modifying the kubelet configuration on the nodes that will be running the kubernetes management components, along with the manifests for the management pieces.
**Would NOT recommend doing this in production**
Kubelet Reserved CPU configuration
(Optional, 1.17 required)
Modify /var/lib/kubelet/config.yaml to ensure that a set of CPUs are reserved for things like the kubelet and system daemons.
In a 24 CPU system the below addition will pin the first four CPUs for system and kubernetes daemons. reservedSystemCPUs: 0,1,2,3
CPU Manager (1.10+ required))
This is discussed in more detail here however, this setting when enabled allows the kubelet to have more “robust” control over how CPU utilisation is allocated to pods. To enable this modify /var/lib/kubelet/config.yaml to ensure that the cpuManagerPolicy: static exists or is modified from none.
Control Plane components
In order for these components to be secured by the CPU Manager we will need to modify their Spec so that they are given the Guaranteed QoS class. We can find the manifests for the control-plane components under /etc/kubernetes/manifests and with the above configuration enabled we can modify these manifests with configuration that will tie them to resources and ensure their stability.
In order to give this QoS class we need to ensure that:
Both the requests and limits match (or that request is ommitted)
The limits for cpu are a whole number (not a fraction)
Modifying the /etc/kubernetes/manifests/kube-apiserver.yaml to have the following resource section, will bind it to a Guaranteed QoS class
The remaining control-plane components will need modifying in the same manner in order to ensure that they all have Guaranteed resource leaving the remaining capacity for other use-cases.
Utilise this “freed” capacity
With some level of protection around the control-plane components we can look into what could make sense to run on this same infrastructure. Both of the above examples should ring-fence resources around processing capacity CPU and application memory. However the control-plane can still be impacted by things like slow I/O, in the case that something else was thrashing the same underlying storage, we could end up in a position where the control-plane components fail or etcd nodes fail due to high latency. A simple solution for this would be to ensure that these two use-cases use different underlying storage, so that neither can impact each other. One other area is system bandwidth, if this additional capacity is used by applications with high bandwidth requirements then it could potentially effect the control-plane components. Again in this scenario consider additional network interfaces that ensure that traffic is completely segregated from the control-plane traffic.
With the above in mind what other utilisation considerations could be taken into consideration?
Use-case: Ideally keeping the use-cases aligned makes it easier from a security perspective as only the same teams would need to interact with the same node.
Application load: No/never
Example workloads that *could be considered:
Logging
Dashboard
Ingress
Load-Balancing
Container registry (more for HA, if supported)
Image scanning
All of the above is a fine balance between getting more utilisation from your bare-metal servers, and ensuring that additional workload is non-impacting to the control-plane whilst introducing minimal operating overhead or security issues.
Networking (load-balancing)
This section is limited to both the networking function of load-balancing and the control-plane for kubernetes. The load-balancing for applications and services that are running within a Kubernetes cluster can be hosted elsewhere and usually is more application focused.
In the event that hardware appliances such as F5s (docs are here) are present then follow the vendor documentation for deploying that particular solution. However in the event we need to roll our own, then we will discuss the architecture decisions and options in this section.
As mentioned above, we require two components for this to be a completely HA and resilient solution:
Virtual IP, ensuring that an active load balance can always be addressed and accessed.
Load-Balancer instance, ensuring traffic is load balanced between Control-plane nodes.
The two software solutions for this that we will be using are keepalived for the Virtual IP address and HAProxy for the load-balancing.
Then finally there are two architectures that we will discuss that can be considered in order to provide a HA design:
External (to the control-plane) Load-Balancer
As with the discussion of stacked vs unstacked control plane nodes (etcd on the same nodes), we also have the architectural decision of co-locating the load-balancing components on the same nodes. This first architecture will utilise two systems external to the Kubernetes nodes to create an external load-balancer pair, that under most circumstances would in a similar manner to a load-balancing appliance.
Pros
Load-Balancer is physically separate from Kubernetes Control pane nodes
Only requires two instances/deployments of the required components
Easy to scale as not tightly coupled to the control plane nodes
Opportunity for Kubernetes services running in the cluster or other hosts to be load-balanced by the same external load-balancer
Cons
Requires it’s own hardware (or virtual hardware)
Additional management and operational overhead
Stacked (on the control-plane node(s)) Load-Balancer
The opposite the above architecture would be locate the load-balancer components locally to the Kubernetes control plane components. Simplifying the architecture, but creating it’s own architectural challenges.
Pros
Simplifies deployment, control plane nodes are always deployed with all of the required components
Scaling becomes simplified, going from 3 -> 5 control plane nodes involves the deployments of 2 more control plane nodes and adding into load balancer/VIP configuration
Reduces the infrastructure requirement as load-balancing shares the same infrastructure as the control plane components
Possibility of one-day having kubeadm manage the load-balancing lifecycle in the same way that it now manages etcd
Cons
Tight coupling, can result in hard to debug networking, performance or configuration issues.
An issue with either of the load-balancing components could have a knock-on effect to the control pane nodes without proper precautions in place.
Stacked Port conflicts
Another thing that can appear confusing with co-locating the load-balancers on the same node(s) as the Kubernetes API control plane components are the port configurations. We can’t have two applications listening on the same port, which means if we try to configuration the load-balancer to expose its services on the standard Kubernetes API-server port (6443) then we can’t also have the api-server trying to use the same port.
The architecture diagram below depicts the load-balancer binding to port 6443 and sending requests to one of the API-Servers listening on port 6444:
In order to allow the API-server to behave as expected we expose the load-balanced API-servers through the standard port (6443) and configure all of the API-servers to bind to the port (6444). This means that there are no port conflicts, but can cause confusion when trying to debug issues e.g. if the load-balancer isn’t behaving as expected or is down then to connect to a specific Kubernetes API-server we need to remember to connect to controlplane0{X}:6444. Finally when using kubeadm to perform the installation we need to do two additional things:
Use the VIP and load-balancer port 6443 --control-plane-endpoint “$VIP_ADDRESS:6443”
Ensure that the actual Kubernetes API-server binds to port 6444 --apiserver-bind-port 6444
Note: The --apiserver-bind-port is required for initialising the first control plane and joining of additional control plane nodes.
The outlier (worker) architecture
It could be possible to have the load-balancing components deployed first on identified worker nodes, which would free up any risk of the either workload causing performance issues or outages. However in this scenario we break the concept of workers being something we care about ( cattle vs pets , whatever the analogy is for not having to worry too much about the infra). If workers are suddenly tied to particular workloads that we need to deeply worry about, then we’re in a position where we’ve broken the model to easily replace, scale and destroy our worker pools.
The other issue is that we would need the workers in place before we can actually deploy our control plane, which introduces more chicken and egg architectural design choices.
With all this in mind, lets look at how we actually would get this deployed …
Getting Kubernetes deployed on Bare-Metal
This section will detail the majority of steps that are required to deploy the load-balancing and the Control-plane components of a cluster in a typical bare-metal environment. Worker nodes aren’t covered, but as this deployment will be making use of kubeadm then the workers will be managed through the kubeadm join command.
For workloads that target specific nodes (e.g. nodes with lower core higher frequency for single thread or GPU(s)) then we should label the nodes and use a nodeSelector in the spec as detailed here.
Finally, these steps are for Ubuntu.. If you’re deploying on some-other distro the steps or package names shouldn’t be too different in order to install and configure in the same manner.
The Infrastructure
In this deployment, we will be deploying a stacked architecture which means that the control plane nodes will have everything installed on each node:
Kubernetes Control plane components
etcd
Load-Balancer components
The nodes will consist of three Ubuntu 16.04 or 18.04 standard installations with a user that has Sudo installed.. How that OS gets there, for remote installations I can highly recommend plunder (“Shameless plug”). With the bare-metal nodes up, Operating Systems installed and permanent network addresses given we need to consider one final step (due to the VIP), the network addressing for our cluster.
In our deployment we’ll manage this address scheme quite simply, with the first address for the VIP and all subsequent addresses following in parallel.
Example IP address table
Node
Address
VIP
10.0.0.100
controlPlane01
10.0.0.101
controlPlane02
10.0.0.102
controlPlane03
10.0.0.103
The Kubernetes install one-liner
With our infrastructure in place, we can now begin the installation of Kubernetes! The installation will be following the steps from https://kubernetes.io using kubeadm. However a much more condensed version is below, I like to refer to it as a one-liner as it is technically a one-liner(ish)…
Once the version is set then the next step will update Ubuntu, update repositories and install all of the components that we need to install a HA Kubernetes cluster.
Set the version
This environment variable is used to determine the version of Kubernetes that will be installed by the below one-liner.
export kVersion="1.17.0-00"
Install all the packages
This will install “everything” needed (on ubuntu) for a control-plane node with load-balancing and high-availability.
Once the above is complete the system is ready to be configured, however ensure that this is repeated on all of the control plane nodes.
Load-balancing the load-balancing
Virtual IP / KeepaliveD configuration
Below are the important sections for the /etc/keepalived/keepalived.conf that will be required on each of the nodes.
Global Definition of the keepalived configuration
1 2 3 4 5 6 7
global_defs { # Name of VIP Instance router_id KubernetesVIP # Enable SNMP Monitoring (Optional) # enable_traps }
Virtual Service Definition (this is where we define the configuration of our VIP)
As mentioned in the comments on the example configuration below, typically the first node 01 we need to set the state to MASTER. The means that on startup that this node will be the node be allocated the VIP first. The priority number is used during the keepalived cluster elections to determine who will become the next MASTER and the highest priority wins.
For further details on these configurations the keepalived documentation can be found here.
vrrp_instance APIServerVIP { # Interface to bind to interface ens192
# This should be set to MASTER on the first node and BACKUP on the other two state MASTER # This should be 50+ lower on the other two nodes to enable the lead election priority 100
# Address of this particular node mcast_src_ip $node_IP
# A unique ID if more than one service is being defined virtual_router_id 61 advert_int 1 nopreempt
# Authentication for keepalived to speak with one another authentication { auth_type PASS auth_pass $bloody_secure_password }
# Other Nodes in Cluster unicast_peer { $other_node_IP $other_node_IP }
# Kubernetes Virtual IP virtual_ipaddress { 10.0.0.100/24 }
# Health check function (optional) #track_script { # APIServerProbe #} }
Health check (optional)
This can be used to determine if the Kubernetes API server is up and running, if not fail the VIP to another node, but with the load-balancer performing the same task it’s not a requirement.
1 2 3 4 5 6 7 8
vrrp_script APIServerProbe { # Health check the Kubernetes API Server script "curl -k https://$node_IP:6443" interval 3 timeout 9 fall 2 rise 2 }
Below are the additions to the /etc/haproxy/haproxy.conf that will be there by default, ensure you back up the original before modifying and then append the configuration below. As mentioned here we need to remember that the frontend will expose itself on port 6443, and it will load-balance to the kubernetes API-servers listening on port 6444.
If we wanted to use the flags mentioned above in the section Kubernetes resource control then we can use kubeadm to print out all of the configuration yaml and we can edit the sections that are identified using the kind: key.
Step one: Print configuration and save configuration
We need to remove the advertiseAddress as it defaults to a ridiculous default (not sure why), and edit the bindPort to 6444 as this is what the API-Server needs to listen on in order to not conflict with the load-balancer.
Step three: Edit ClusterConfiguration
We need to add the line controlPlaneEndpoint: "LOAD_BALANCER_DNS:LOAD_BALANCER_PORT" to this section so that it uses our VIP address and uses the port of the load balancer.
Step four: Edit KubeletConfiguration
If we want to use the ReservedCPU functionality then add the line: reservedSystemCPUs: 0,1 (edit for the number of CPUs to save).
If we want to have Guaranteed QOS for our Pods then we can add the line: cpuManagerPolicy: static.
We can then apply our configuration with the command:
1
sudo kubeadm init --config ./cluster.yaml
This will initialise our control plane on the first node and print out the subsequent join command for other control plane nodes:
When joining the remaining nodes to the cluster, ensure that you add the --apiserver-bind-port 6444 to ensure that the Api-server binds on a different port to the load balancer sitting above it.
With the VIP and load-balancers up and running, along with our cluster initialised we can now add in our additional nodes and build out a HA/Load-balancer Kubernetes cluster.
1 2 3 4 5
$ kubectl get nodes NAME STATUS ROLES AGE VERSION controlplane01 Ready master 2m33s v1.17.0 controlplane02 Ready master 108s v1.17.0 controlplane03 Ready master 56s v1.17.0
To test the cluster, we can stop and start the VIP with sudo systemctl stop keepalived and ensure that kubectl get nodes continues to act as expected. Rebooting of nodes will also create the same experiences as having node failures. We should be able to see logs showing that keepalived is moving our VIP to working nodes and ensuring that access always remains into the running cluster.
Considerations for an unstacked load-balancer
The above guide details all of the steps required to build a HA Kubernetes cluster that has the load-balancing components co-located on the same nodes as the Kubernetes components. If we wanted to build an external or unstacked load-balancing pair of nodes then the process is very similar and covered in brief below.
On both of the load-balancing nodes (loadBalancer01/02) we will need to install the components for the load-balancing:
1
apt-get install -y haproxy keepalived
With these components installed on both nodes we can now configure them in the exact same way as before except. The two load-balancing nodes will need the VIP and HAProxy configured in an almost identical manner, however the only consideration is the ports of the Kubernetes API server. As the load-balancer and the Kubernetes API-Server will be on different nodes they won’t have to deal with a port conflict, this means that we can leave the API-Server listening on power 6443 on the controlPlane01/02/03 nodes.
Using Nginx instead of HAProxy
The above examples all use HAProxy as it’s been my default, however Nginx can also be used as a load-balancer that sits between the VIP and the Kubernetes API-server. Below is an identical configuration to the HAProxy configuration above that can be appended to /etc/nginx/nginx.conf:
 The product was a complete failure, but look at it !
The product was a complete failure, but look at it !